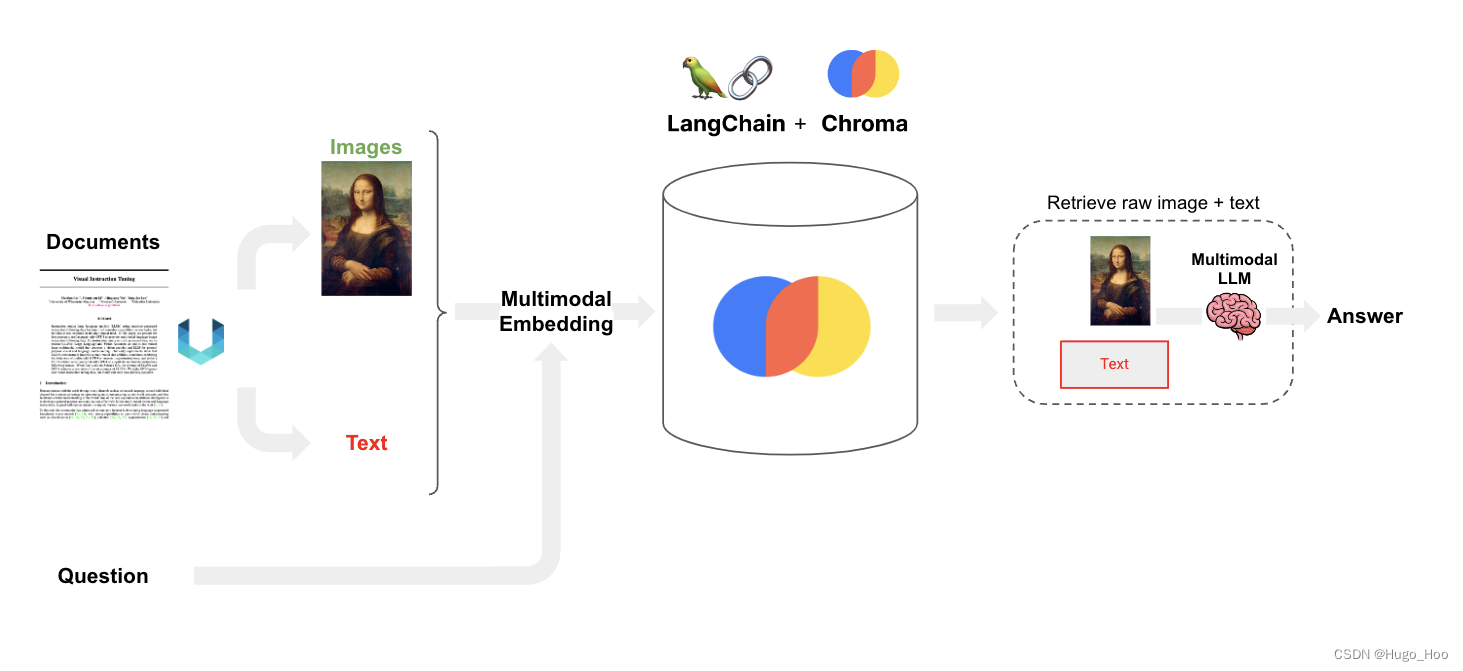
Chroma 多模态 RAG
许多文档包含多种内容类型,包括文本和图像。
然而,大多数 RAG 应用中,图像中捕获的信息往往被忽略。
随着多模态 LLM 的出现,如 GPT-4V,值得考虑如何在 RAG 中利用图像:
选项 1:
- 使用多模态嵌入(例如 CLIP)来嵌入图像和文本
- 使用相似性搜索检索图像和文本
- 将原始图像和文本片段传递给多模态 LLM 进行答案合成
选项 2:
- 使用多模态 LLM(例如 GPT-4V、LLaVA 或 FUYU-8b)从图像生成文本摘要
- 嵌入并检索文本
- 将文本片段传递给 LLM 进行答案合成
选项 3:
- 使用多模态 LLM(例如 GPT-4V、LLaVA、或 FUYU-8b)直接从图像和文本中生成答案
- 使用引用原始图像嵌入和检索图像摘要
- 将原始图像和文本块传递到多模态LLM以进行答案合成
本文重点介绍选项1 。
- 我们将使用 Unstructed 来解析文档 (PDF) 中的图像、文本和表格。
- 我们将使用 Open Clip多模态嵌入。
- 我们将使用支持多模式的 Chroma。
Packages
对于 unstructured ,您的系统中还需要 poppler (安装说明)和 tesseract (安装说明)。
! pip install -U langchain openai chromadb langchain-experimental # (newest versions required for multi-modal)
#lock to 0.10.19 due to a persistent bug in more recent versions
! pip install "unstructured[all-docs]==0.10.19" pillow pydantic lxml pillow matplotlib tiktoken open_clip_torch torch
数据加载
分割 PDF 文本和图像
让我们看一个包含有趣图像的 pdf 示例。
1/ J Paul Getty 博物馆的艺术品:
- 这是一个包含 PDF 和已提取图像的 zip 文件。
- https://www.getty.edu/publications/resources/virtuallibrary/0892360224.pdf
2/ 国会图书馆的著名照片:
- https://www.loc.gov/lcm/pdf/LCM_2020_1112.pdf
- 我们将在下面使用它作为示例
我们可以使用下面的 Unstructed 中的 partition_pdf 来提取文本和图像。
要提供它来提取图像:
extract_images_in_pdf=True
如果使用此 zip 文件,那么您只需使用以下命令即可简单地处理文本:
extract_images_in_pdf=False
# Folder with pdf and extracted images
path = "/Users/rlm/Desktop/photos/"
# Extract images, tables, and chunk text
from unstructured.partition.pdf import partition_pdf
raw_pdf_elements = partition_pdf(
filename=path + "photos.pdf",
extract_images_in_pdf=True,
infer_table_structure=True,
chunking_strategy="by_title",
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path,
)
# Categorize text elements by type
tables = []
texts = []
for element in raw_pdf_elements:
if "unstructured.documents.elements.Table" in str(type(element)):
tables.append(str(element))
elif "unstructured.documents.elements.CompositeElement" in str(type(element)):
texts.append(str(element))
Multi-modal embeddings with our document(我们的文档的多模态嵌入)
我们将使用 OpenClip 多模态嵌入。
我们使用更大的模型以获得更好的性能(在 langchain_experimental.open_clip.py 中设置)。
model_name = "ViT-g-14"
checkpoint = "laion2b_s34b_b88k"
import os
import uuid
import chromadb
import numpy as np
from langchain_community.vectorstores import Chroma
from langchain_experimental.open_clip import OpenCLIPEmbeddings
from PIL import Image as _PILImage
# Create chroma
vectorstore = Chroma(
collection_name="mm_rag_clip_photos", embedding_function=OpenCLIPEmbeddings()
)
# Get image URIs with .jpg extension only
image_uris = sorted(
[
os.path.join(path, image_name)
for image_name in os.listdir(path)
if image_name.endswith(".jpg")
]
)
# Add images
vectorstore.add_images(uris=image_uris)
# Add documents
vectorstore.add_texts(texts=texts)
# Make retriever
retriever = vectorstore.as_retriever()
RAG
vectorstore.add_images 将存储/检索图像作为 base64 编码字符串。
这些可以传递给 GPT-4V。
import base64
import io
from io import BytesIO
import numpy as np
from PIL import Image
def resize_base64_image(base64_string, size=(128, 128)):
"""
Resize an image encoded as a Base64 string.
Args:
base64_string (str): Base64 string of the original image.
size (tuple): Desired size of the image as (width, height).
Returns:
str: Base64 string of the resized image.
"""
# Decode the Base64 string
img_data = base64.b64decode(base64_string)
img = Image.open(io.BytesIO(img_data))
# Resize the image
resized_img = img.resize(size, Image.LANCZOS)
# Save the resized image to a bytes buffer
buffered = io.BytesIO()
resized_img.save(buffered, format=img.format)
# Encode the resized image to Base64
return base64.b64encode(buffered.getvalue()).decode("utf-8")
def is_base64(s):
"""Check if a string is Base64 encoded"""
try:
return base64.b64encode(base64.b64decode(s)) == s.encode()
except Exception:
return False
def split_image_text_types(docs):
"""Split numpy array images and texts"""
images = []
text = []
for doc in docs:
doc = doc.page_content # Extract Document contents
if is_base64(doc):
# Resize image to avoid OAI server error
images.append(
resize_base64_image(doc, size=(250, 250))
) # base64 encoded str
else:
text.append(doc)
return {"images": images, "texts": text}
目前,我们使用 RunnableLambda 格式化输入,同时向 ChatPromptTemplates 添加图像支持。
我们的可运行程序遵循经典的 RAG 流程 -
- 我们首先计算上下文(在本例中是“文本”和“图像”)和问题(这里只是一个 RunnablePassthrough)
- 然后我们将其传递到提示模板中,这是一个自定义函数,用于格式化 gpt-4-vision-preview 模型的消息。
- 最后我们将输出解析为字符串。
from operator import itemgetter
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import ChatOpenAI
def prompt_func(data_dict):
# Joining the context texts into a single string
formatted_texts = "\n".join(data_dict["context"]["texts"])
messages = []
# Adding image(s) to the messages if present
if data_dict["context"]["images"]:
image_message = {
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{data_dict['context']['images'][0]}"
},
}
messages.append(image_message)
# Adding the text message for analysis
text_message = {
"type": "text",
"text": (
"As an expert art critic and historian, your task is to analyze and interpret images, "
"considering their historical and cultural significance. Alongside the images, you will be "
"provided with related text to offer context. Both will be retrieved from a vectorstore based "
"on user-input keywords. Please use your extensive knowledge and analytical skills to provide a "
"comprehensive summary that includes:\n"
"- A detailed description of the visual elements in the image.\n"
"- The historical and cultural context of the image.\n"
"- An interpretation of the image's symbolism and meaning.\n"
"- Connections between the image and the related text.\n\n"
f"User-provided keywords: {data_dict['question']}\n\n"
"Text and / or tables:\n"
f"{formatted_texts}"
),
}
messages.append(text_message)
return [HumanMessage(content=messages)]
model = ChatOpenAI(temperature=0, model="gpt-4-vision-preview", max_tokens=1024)
# RAG pipeline
chain = (
{
"context": retriever | RunnableLambda(split_image_text_types),
"question": RunnablePassthrough(),
}
| RunnableLambda(prompt_func)
| model
| StrOutputParser()
)
测试检索并运行 RAG
from IPython.display import HTML, display
def plt_img_base64(img_base64):
# Create an HTML img tag with the base64 string as the source
image_html = f'<img src="data:image/jpeg;base64,{img_base64}" />'
# Display the image by rendering the HTML
display(HTML(image_html))
docs = retriever.invoke("Woman with children", k=10)
for doc in docs:
if is_base64(doc.page_content):
plt_img_base64(doc.page_content)
else:
print(doc.page_content)

chain.invoke("Woman with children")
'Visual Elements:\nThe image is a black and white photograph depicting a woman with two children. The woman is positioned centrally and appears to be in her thirties. She has a look of concern or contemplation on her face, with her hand resting on her chin. Her gaze is directed away from the camera, suggesting introspection or worry. The children are turned away from the camera, with their heads leaning against the woman, seeking comfort or protection. The clothing of the subjects is simple and worn, indicating a lack of wealth. The background is out of focus, drawing attention to the expressions and posture of the subjects.\n\nHistorical and Cultural Context:\nThe photograph was taken by Dorothea Lange in March 1936 and is titled "Destitute pea pickers in California. Mother of seven children. Age thirty-two. Nipomo, California." It was taken during the Great Depression in the United States, a period of severe economic hardship. The woman in the photo, Florence Owens Thompson, was a Cherokee from Oklahoma. The image is part of the Farm Security Administration-Office of War Information Collection, which aimed to document and bring attention to the plight of impoverished farmers and workers during this era.\n\nInterpretation and Symbolism:\nThe photograph, often referred to as "Migrant Mother," has become an iconic symbol of the Great Depression. The woman\'s expression and posture convey a sense of worry and determination, reflecting the resilience and strength required to endure such difficult times. The children\'s reliance on their mother for comfort underscores the family\'s vulnerability and the burdens placed upon the woman. Despite the hardship conveyed, the image also suggests a sense of dignity and maternal protectiveness.\n\nThe text provided indicates that Florence Owens Thompson was a strong and leading figure within her community, which contrasts with the vulnerability shown in the photograph. This dichotomy highlights the complexity of Thompson\'s character and the circumstances of the time, where even the strongest individuals faced moments of hardship that could overshadow their usual demeanor.\n\nConnections Between Image and Text:\nThe text complements the image by providing personal insight into the subject\'s feelings about the photograph. It reveals that Thompson resented the photo because it did not reflect her strength and leadership qualities. This adds depth to our understanding of the image, as it suggests that the moment captured by Lange is not fully representative of Thompson\'s character. The photograph, while powerful, is a snapshot that may not encompass the entirety of the subject\'s identity and life experiences.\n\nThe final line of the text, "They\'re willing to have me entertain them during the day, but as soon as it starts getting dark, they all go off, and leave me!" could be interpreted as a metaphor for the transient sympathy of society towards the impoverished during the Great Depression. People may have shown interest or concern during the crisis, but ultimately, those suffering, like Thompson and her family, were left to face their struggles alone when the attention faded. This line underscores the isolation and abandonment felt by many during this period, which is poignantly captured in the photograph\'s portrayal of the mother and her children.'
我们可以看到 LangSmith 跟踪中检索到的图像。
总结:
本文件详细介绍了如何使用 Chroma 实现多模态检索增强生成 (RAG)。主要内容包括系统的整体架构、关键组件、代码实现以及应用示例。文中展示了如何将文本和图像数据结合,利用检索技术增强生成模型的性能。具体代码部分提供了详细的实现步骤,并辅以注释以帮助理解。
扩展知识
多模态学习:
多模态学习指的是结合多种不同类型的数据(如文本、图像、音频等)进行模型训练,以提升模型的理解和生成能力。通过将不同模态的数据相结合,模型可以获取更丰富的信息,从而在任务执行中表现出色。
检索增强生成(RAG):
RAG 是一种结合检索和生成的技术,通过在生成过程中引入外部知识库的检索结果,提高生成内容的准确性和相关性。这种方法在处理开放域问答和其他需要动态知识更新的任务中表现出色。
Chroma:
Chroma 是一个用于多模态数据处理的工具,可以帮助开发者高效地处理和整合不同类型的数据。使用 Chroma,可以方便地实现数据的预处理、特征提取和模态间的对齐,从而提升模型的整体性能。
本文档通过具体的代码示例,展示了如何使用 Chroma 实现多模态 RAG,并提供了详细的注释以帮助理解每一步的实现。希望通过本教程,读者能够掌握多模态 RAG 的基本概念和实现方法,并应用到实际项目中。